
Introduction
In the rapidly evolving landscape of artificial intelligence, language models are becoming increasingly sophisticated. However, even the most advanced models can struggle to provide accurate and contextually relevant answers when faced with complex or novel queries. This is where Retrieval-Augmented Generation (RAG) emerges as a powerful solution. RAG bridges the gap between pre-trained language models and real-world knowledge, allowing AI systems to access and leverage external information to enhance their responses. In essence, RAG empowers language models to "learn" on the fly, adapting to new information and providing more informed and reliable answers. This blog post is designed as an entry point, offering a comprehensive overview of RAG for beginners.
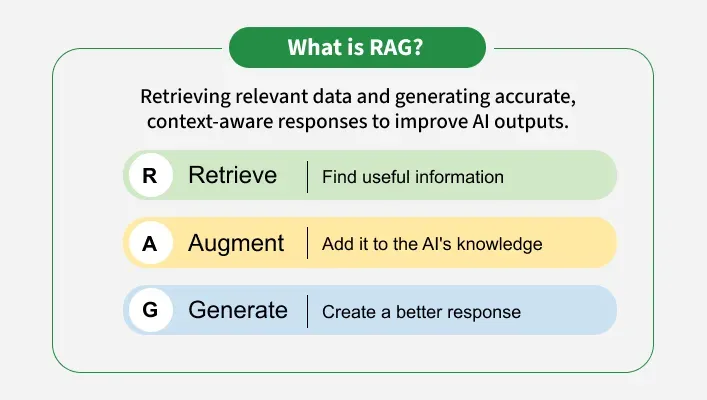
Image Source: geeksforgeeks
What is Retrieval-Augmented Generation (RAG)?
At its core, RAG is an architecture that enhances the capabilities of language models (LLMs) by enabling them to retrieve relevant information from an external knowledge source before generating a response. Imagine a language model as a talented writer, but one who sometimes lacks specific knowledge on certain topics. RAG acts as a research assistant, providing the writer with the necessary information to create a well-informed and accurate piece.
The RAG process typically involves three key steps:
- Retrieval: Given a user query, the system searches a vast knowledge base (e.g., a collection of documents, a database, or the web) to identify relevant information. This retrieval process often involves techniques like semantic search, which aims to find information that is semantically similar to the query, even if it doesn't contain the exact keywords.
- Augmentation: The retrieved information is then combined with the original user query to create an augmented input. This augmented input provides the language model with additional context and knowledge to inform its response. The way the retrieval context is injected also matters, you want to have it in a way that model can understand that it is given an external knowledge.
- Generation: Finally, the augmented input is fed into a language model, which generates a response based on both the original query and the retrieved information. The model leverages the retrieved knowledge to produce a more accurate, informative, and contextually relevant answer.
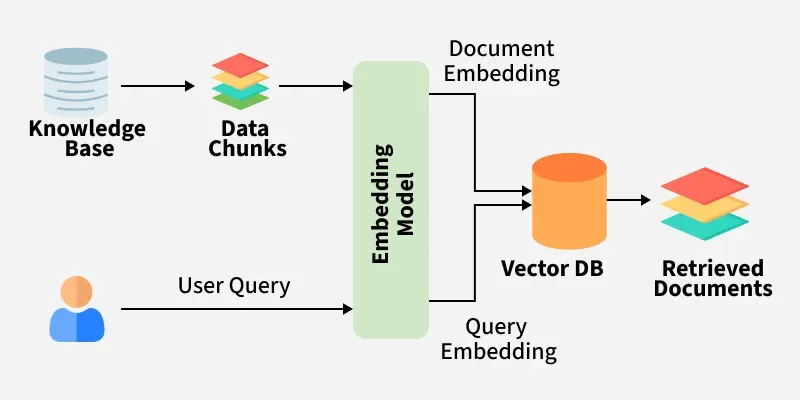
Image Source: geeksforgeeks
Types of RAG Approaches
There are various approaches to implementing RAG, each with its own strengths and weaknesses. Here are a few common types:
Naive RAG
This is the simplest form of RAG, where the retrieved context is directly appended to the query and fed into the language model. While easy to implement, this approach can sometimes overwhelm the model with too much information, leading to suboptimal results.
Advanced RAG
This encompasses a range of techniques designed to improve the quality and relevance of the retrieved context. Some advanced RAG techniques include:
- Re-ranking: Ranking the retrieved documents or passages based on their relevance to the query, ensuring that the most relevant information is presented to the language model first.
- Query Routing: Directing the query to the most appropriate knowledge source based on its content, improving the efficiency of the retrieval process.
- Fine-tuning Retrieval Models: Training the retrieval model to better understand the nuances of the language model and retrieve information that is more likely to be helpful.
- Hypothetical Document Embedding (HyDE): Use the LLM to generate a hypothetical document based on the query, then embed the generated document and use that embedding for retrieval. This can be useful when the query itself is not very informative.

Image Source: geeksforgeeks
RAG vs. Fine-tuning: Which One is Right for You?
RAG is often compared to fine-tuning, another technique for adapting language models to specific tasks or domains. While both RAG and fine-tuning can improve the performance of language models, they differ in several key aspects:
- Knowledge Updates: RAG allows for easy updates to the knowledge base without requiring retraining of the language model. This is a significant advantage when dealing with rapidly changing information. Fine-tuning, on the other hand, requires retraining the model whenever the underlying data changes.
- Transparency: RAG provides transparency into the sources of information used to generate the answer, making it easier to verify the accuracy and reliability of the response. Fine-tuning can make it more difficult to trace the origins of the model's knowledge.
- Cost: RAG is typically less computationally expensive than fine-tuning, as it doesn't require updating the model's parameters. Fine-tuning can be resource-intensive, especially for large language models.
When to use RAG:
- You need to incorporate external knowledge into the language model's responses.
- The knowledge base is constantly evolving.
- Transparency and traceability are important.
- You want to avoid the cost and complexity of retraining the model.
When to use Fine-tuning:
- You want to adapt the language model to a specific task or domain.
- The knowledge base is relatively stable.
- You need to optimize the model for a particular performance metric.
- You have a large, high-quality dataset for training.
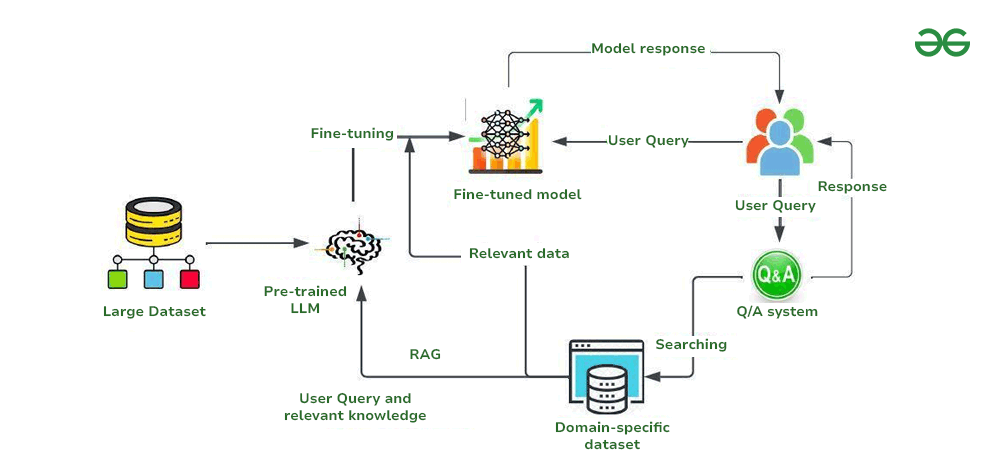
Image Source: geeksforgeeks
Key Benefits of Using RAG
- Improved Accuracy and Informativeness: By grounding the language model's responses in external knowledge, RAG helps to reduce the occurrence of factual errors and improve the overall quality of the generated text.
- Enhanced Contextual Relevance: RAG enables language models to provide more contextually relevant answers by considering the specific information retrieved from the knowledge base.
- Adaptability to New Information: RAG allows language models to adapt to new information without requiring retraining, making them more resilient to change and more capable of handling novel queries.
- Reduced Hallucinations: By grounding the answers in reliable knowledge, RAG helps to minimize the occurrence of "hallucinations," where the language model generates false or nonsensical information.
Challenges of RAG
- Retrieval Quality: The performance of RAG is highly dependent on the quality of the retrieval process. If the retrieval system fails to identify relevant information, the language model will be unable to generate an accurate or informative response.
- Context Length Limitations: Language models typically have a limited context length, which restricts the amount of information that can be fed into the model at one time. This can be a challenge when dealing with large or complex documents.
- Noise in Retrieved Context: The retrieved context may contain irrelevant or contradictory information, which can confuse the language model and degrade its performance.
- Computational Cost: While RAG is typically less computationally expensive than fine-tuning, the retrieval process can still add significant overhead, especially when dealing with large knowledge bases.
- Evaluation Complexity: Evaluating the performance of RAG systems can be challenging, as it requires assessing both the accuracy of the retrieved information and the quality of the generated response.
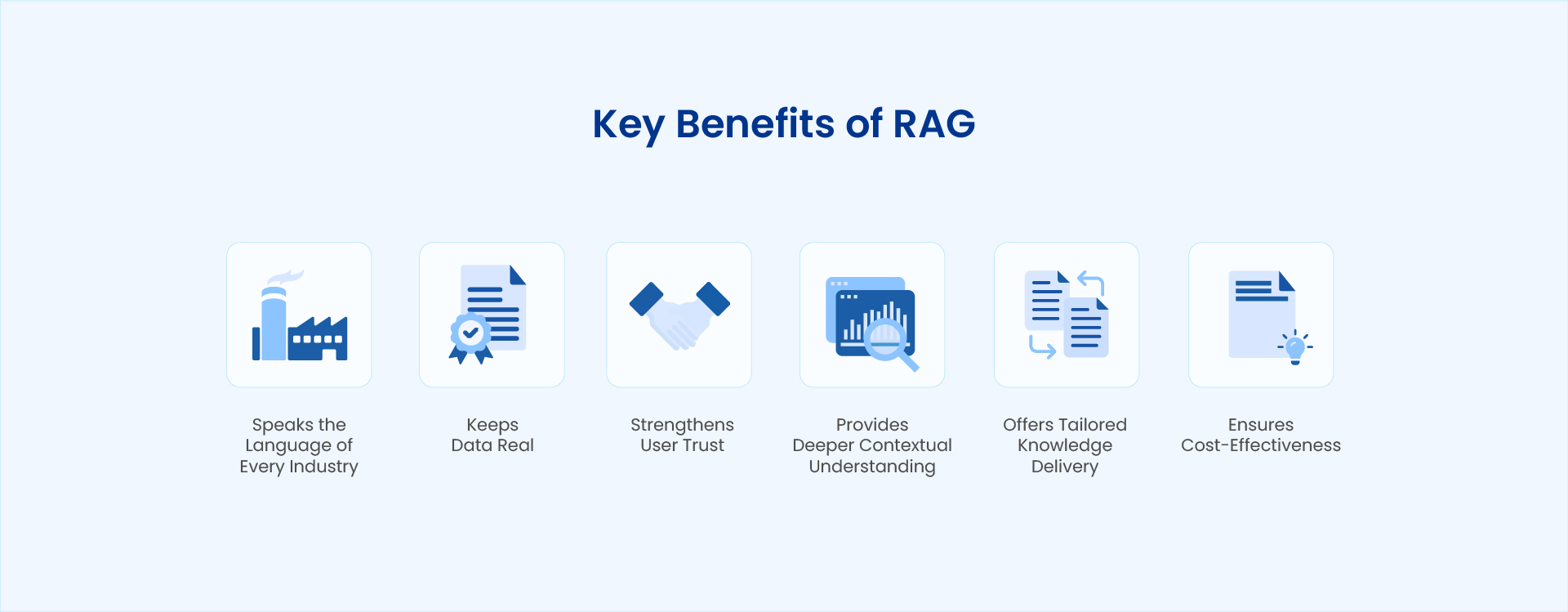
Image Source: geeksforgeeks
Conclusion
Retrieval-Augmented Generation is a powerful technique that enhances the capabilities of language models by integrating them with external knowledge sources. By enabling language models to access and leverage real-world information, RAG can improve their accuracy, informativeness, and contextual relevance. While RAG presents its own challenges, the benefits it offers make it a valuable tool for a wide range of applications, from question answering and chatbot development to content generation and knowledge discovery. As AI continues to evolve, RAG is poised to play an increasingly important role in shaping the future of intelligent systems.
● Contact Me
Get in touch
ahzaaf.ajin@gmail.com